点云预测亲和力
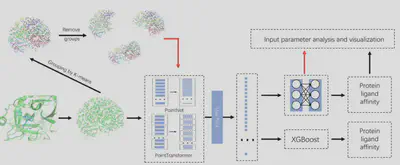
- 首先使用Python和Openbabel对PDBBind数据进行处理产生点云数据
- 进一步提升数据处理的性能,使用C++加速点云产生
- 为了对比Python和C++的速度,使用了高通量分子动力学框架HTMD体素化方法、Pafnucy的预处理方法和分子描述法IFPScore和PSH(Persistent Spectral Hypergraph)
- 测试了PointNet、PointTransformer和不同深度卷积网络的计算时间,不同的样本数量被用于每个预测,其中Pafnucy(20),ResAtom(5),PointNet(5,24),PointTransformer(5)
Python用于读文件
C语言用于体素化进程
在HTMD中网格为15、25、35埃
Pafnucy方法和其他方法作为分子描述器,均用Python编写
数据预处理:
- 训练集:PDBbind-2016包含4057个蛋白配体复合物。核心集作为测试集,剩余的3772条数据作为训练集和验证集 为了测试模型在更大数据集中的性能,结合了精炼集和通用集作为扩展数据集
Openbabel、Pymol
预处理规则:
① 删除肽配体(590)
② 删除包含共价键配体的条目(379)
③ 删除不完整配体(481)
④ 分离测试集和训练集
⑤ 获取扩展集(11327 data)
⑥ 转换点云前,溶剂、金属、离子被剔除
不同原子贡献:
① 七种原子类型通道:氢、碳、氮、氧、磷、硫、卤素
② 原子样本从1024增加到2048
③ 精炼集和扩展集的理化性质,包含芳香性、杂原子、极性氢、非极性氢、氢键接收、氢键发出作为额外的通道进行训练
神经网络架构:
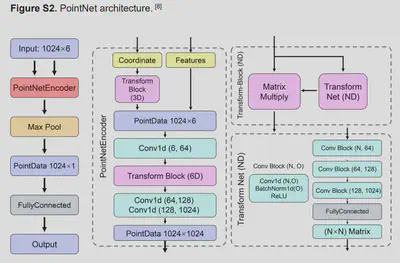
通过点云的旋转增加点云数量(24次) 平台架构:Intel Xeon Gold 6248、Tesla V100S 32G双精度 优化器:SGD Lr:0.001 for refined、0.003 for extended Loss Function:SmoothL1Loss PointNet和PointTransformer的测试集:CAST-2016 模型性能指标:Person相关系数、斯皮尔曼相关系数、均方根误差、均值绝对误差 测试模型:Kdeep、Pafnucy、DeepAtom、APMNet、PSH-GBT、TopBP(complex)
PointTransformer特征
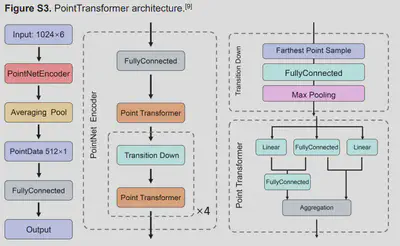
一个PointTransformer可以产生512条特征
总特征维数为 10(XGBoost)* 512(PointTransformer) = 10*512
重复训练30次
训练集PDBbind-2007、PDBbind-2013和PDBbind-2016分别包含110530、276430、3772*30个特征
XGBoost构建模型、sklearn’ RandomizedSearchCV寻找超参数
训练100次计算平均和标准偏差
Chi
Doctor of Bioengineering
My research interests include bioinformatics, deep learning and big data mining.